03-Application-Architecture Backend Design-Patterns System-Design-Basic-Concepts
<< ---------------------------------------------------------------- >>
--- Last Modified: $= dv.current().file.mtime
Partitioning(sharding)
<< ---------------------------------------------------------------- >>
the DB gets too large and infeasible for a single system → replication will not solve this since the DB will not fit in one node → Partition the DB(sharding)
Range Based Partitioning
Partition the DB based off ranges. such as A-Z value of a start of a column. +:
- similar keys on the smae node so good for locality and range queries
- Since the partitions will be on different computers there will have to be network requests to get all the data and the relevants being close to each other is good -:
- hot spots
- some ranges will much more data than other ranges(ranges will not be equal)
Hash Ranged Based Partitioning
You hash the indexes the ranges is based on and set ur ranges based on the hash numbers.
+: 1. relatively even distribution -: 2. no data locality for range queries
Secondary Index Partitioning
You basically keep a second sorted copy on each partition of the data.
For example you can do the first index by hashing the names while doing the second index by their values.
+:
- No need to perform any extra write over the network -:
- to find all entries with the secondary index all partitions will need to be read.
Global Secondary Index:
It is a new copy again on the same shard. Last one the secondary shard was based on the local shard data → this one is global
So if sth has a secondary written in the first shard but its primary is in the second it will have to be written to both shards. This will require DISTRIBUTED TRANSACTIONS.
+:
- reads using the secondary index will only require one read -:
- might have to write to multiple nodes which requires Distributed transactions.
Two Phase Commit - Distributed Transactions
Cross Partition Writes, Global secondary indexes need this because we need atomicity. becuase we cant have some writes succeed and some not as that would give us incorrect reads.
How it works: Coordinator node will reach out to the first node, the first node runs a local transaction to see if it will cause any errors or not if its ok →
grab the DB lock so nothing else modifies it and send an ok to the coordinator →
coordinator sends the message to the second DB and repeat →
if not ok send a message to the Coordinator and the coordinator will send an abort message to the first DB and unlock. If fine the coordinator will send a commit message to the two DBs and unlock and send an OK to the coordinator node.
Cons: Too many points of failure: Coordinator node goes down in the middle of the operation: locks are grabbed and no one can touch those nodes.
Receiver DB goes down: Transaction cant commit and coordinator willhave to send messages until it hears an OK which will only happen when it comes back up
Consistent Hashing:
Partitioning Rebalancing
When we are adding new nodes or shutting down old ones how should we change how the data is distributed?
Solution: consistent hashing
how to make sure if a size of our cluster changes a min amount of data is sent over the network from one node to another.
Great for partitioning and load balancing
How to do it: You pick a k for exmaple 3 here
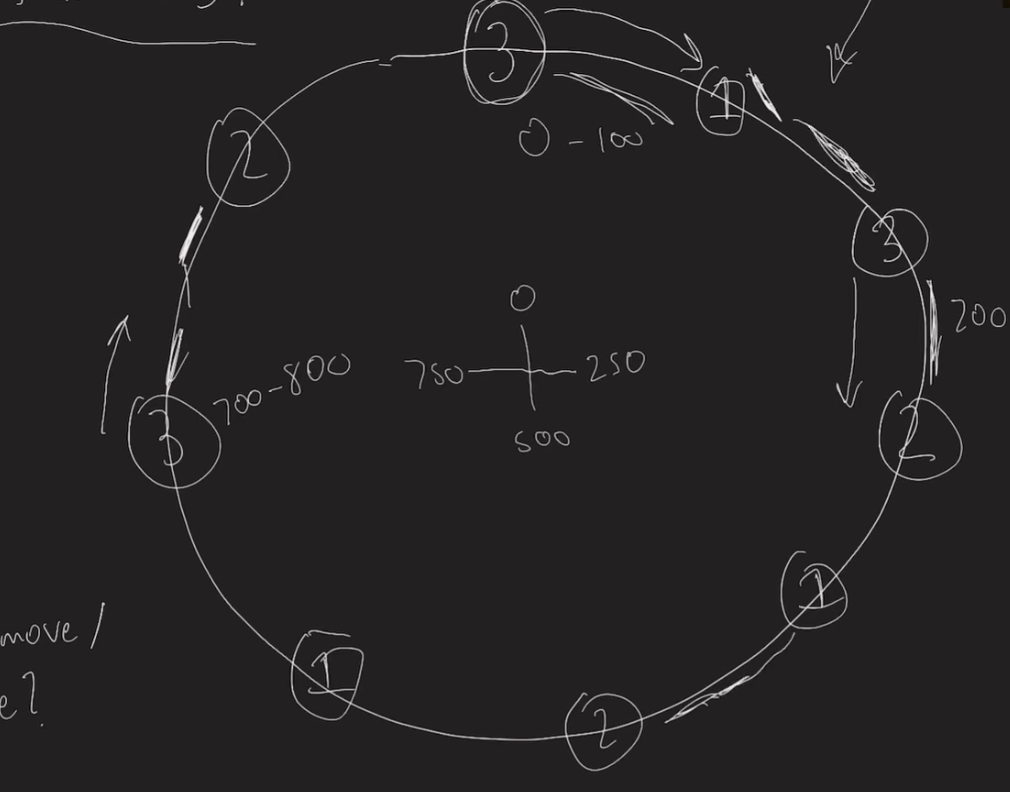 you basically have a circle that you go around with ranges to see what node the hash will be sent to. if a node goes down you scrub it from the range and update the distances.
if a new node is added you do the same thing in the circle and divide it further by adding it in.
you basically have a circle that you go around with ranges to see what node the hash will be sent to. if a node goes down you scrub it from the range and update the distances.
if a new node is added you do the same thing in the circle and divide it further by adding it in.
You can also do total fixed number of partitions per system instead of per node.
Dynamic Partitioning
The database could be set up to rebalance it self instead of someone doing it manually
Linearizable Databases
A database system that is both fault tolerant and its writes happen in order. Meaning if we know the order of the writes, our reads will never go back in time.
So how do we order our writes? Single leader → replicatoin log Multi leader/ leaderless → version vectors/Lamport clock Version vectors take o(n) space. Lamport Clock o(1) space. What they are: you have two clients and trying to make concurrent writes to the database and were trying to order them: They all (clients, DB) have a local counter that you increment everytime you make a write, by taking the max of the counter of the DB the write is going to and the clients counter. To order it you sort by the order of the counters and the Database nodes Nodes(A, B) → (A, 1), (B, 1), (B, 2), (A, 3).
Since we are arbitrarily deciding the ordering between nodes, this still does not the DB linearizable because we are making the ordering after the fact through the arbitration.
For example in a multi-leader system this is not linearizable: Since there is a certain amount of time that it takes for the nodes to communicate, if a certain value has been rewritten, it will take time for the leaderless or multileader to sync the values, thus making the DB not linearizable.
Single Leader Replication: Replication Log is also not linearizable. Since there is time between the write being made to the leader and the write being propogated to the followers, if the leader goes down it makes the system have stale reads, which makes our system not be fault tolerant When nodes fail we still need to make sure our writes are in order
Total Order Broadcast
- every node has to agree on the order of the writes
- in the face of faults we cannot lose any writes
We achieve this using distributed Consensus
Distributed Consensus
Raft
builds a distributed log which is linearizable.
The log has an operation and a turn number. The system has one leader and multiple followers being asynced.
Raft Leader Election:
Each node has an Epoch number: the leader sends heartbeats(pings) periodically to the followers and if it goes down the followers know that.
If havent heard from the leader, you start an election the first node that proposes the election becomes the candidate and increments the previous Epocn number of the leader. (each node waits an arbitrary amount of time after no heartbeat so that not all nodes call for an election at once)
During the Election:
- either the leader is back online and gets the message for the new election
- it says ok I’m a follower now
- The other followers update the epoch number that they follow to the epoch number of the current candidate.
- if the epoch number of the one of the followers if higher(there already was a leader for that term) then it sends a no signal to the candidate
- each follower has to check that their log is behind or as up to date as the new leader being elected, if it is they will vote for the new leader.
- If it receives votes from a quoroum then it becomes the new leader.
- Old leaders cant come back due to fencing tokens
- Their epoch number is lower, so if they propose a write with this lower epoch number than the current term we know it is an old leader and it has to be updated to a follower.
- Leader has an up to date log and can backfill stale nodes. The leader could be the not most up to date node(a new write couldve been sent to only a couple of the nodes thus not being enough for a quoroum)
- Old leaders cant come back due to fencing tokens
Raft Writes
The logs include the operation and the epoch number of the leader that wrote them. If a log is stale:
Writes backfill logs:
- only one leader per term
- successful writes must make log fully up to date
- meaning if two logs have the same term number at the same index, they must be identical prior to the index.
How it works:
- Leader proposes a write by sending the operation and the index of the last write
- if the followers say that they are not at the same index of the log as the leader they reject the log → the leader will have to decrement the index and send that write to the node until it is up to date. → then make the write
Conclusion:
- builds fault tolerant linearizable storage
- it is slow since all writes and depending on the implementation sometimes all reads as well have to go through the leader.
- Even though it is fault tolerant it doesnt replace two phase commit.
Coordination Services
Consensus is slow, but sometimes we nee it. IPs for servers and databases, replication schemas, partitioning breakowns are stored as key-value pairs in a reliable way in the coordination service. 2 most famous are zookeeper and etcd(runs on raft).
ZooKeeper
Additional functionality You have a Sync keyword that you can send to the leader, it will propogate it to the followers and make them catch up on their logs, making sure that any read from the is linearizable, until there is another write. If you want linearizability but without this you have to make all the reads from the leader which is a lot slower
This is too slow for the application data, only key piecese of data of configuration for the backend that need to be current should be on this.