Untitled.md
<< ---------------------------------------------------------------- >>
--- Last Modified: $= dv.current().file.mtime
Count
<< ---------------------------------------------------------------- >> https://www.youtube.com/watch?v=X83DFlt15Xw&list=PLjTveVh7FakJOoY6GPZGWHHl4shhDT8iV&index=19
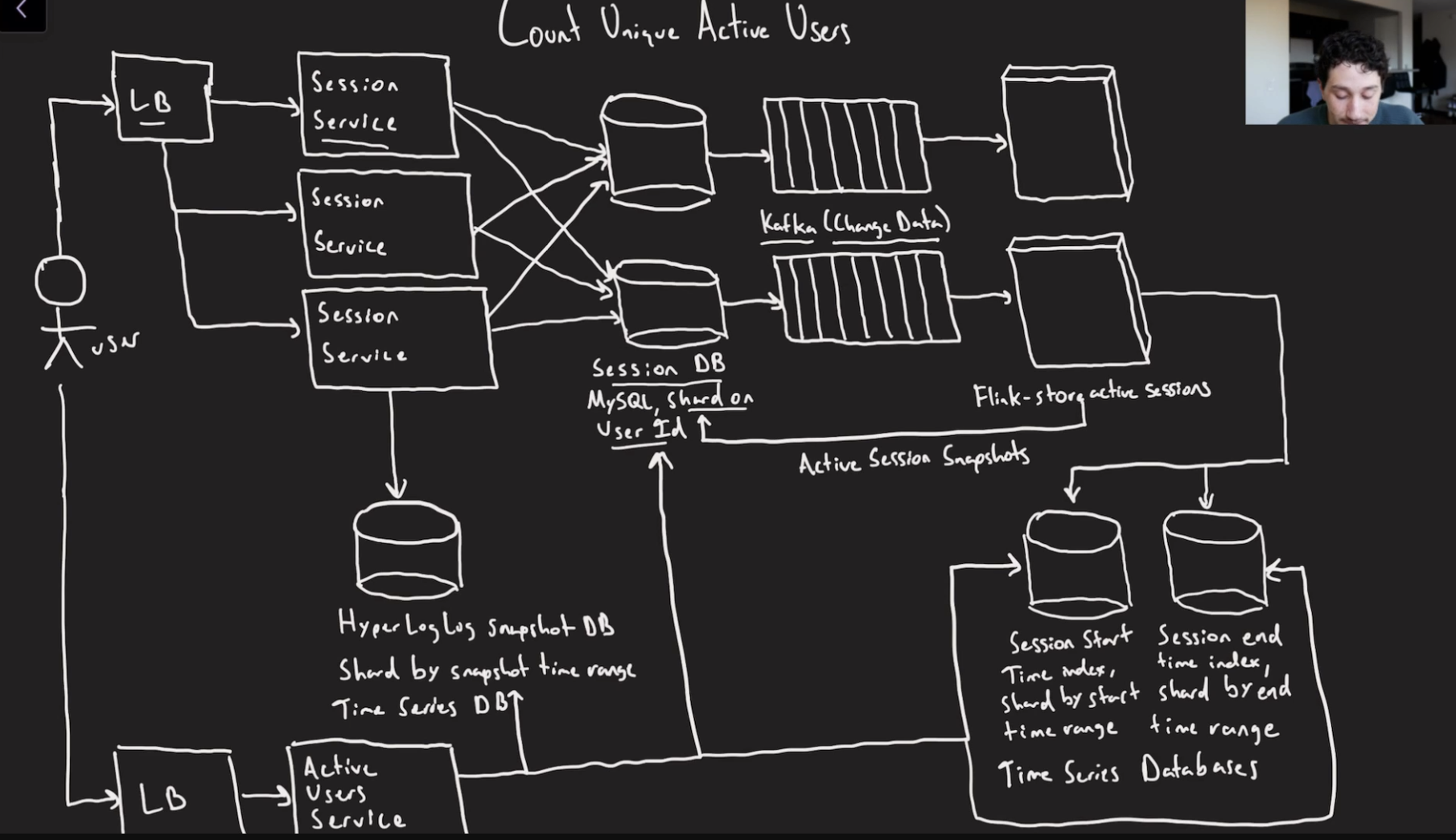
You can do snapshots and normal query hybrid but snapshots will be very expensive for the amount of data they generate since you also need to have kafka and flink nodes to create the snapshots.
→ hyperlog logs Its a probabilistic approach