Untitled.md
<< ---------------------------------------------------------------- >>
--- Last Modified: $= dv.current().file.mtime
Maps
<< ---------------------------------------------------------------- >>
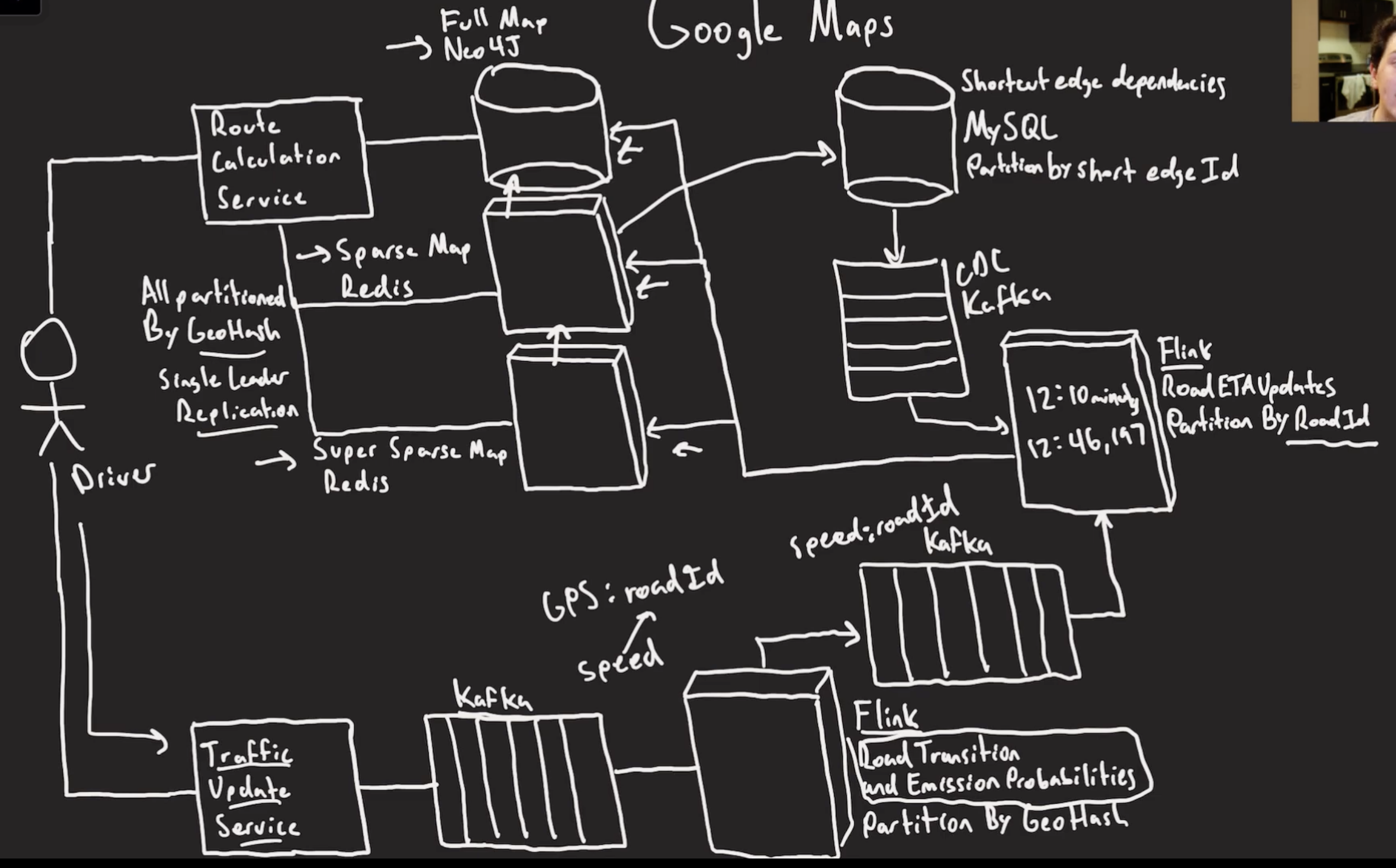
You keep two sets of sparse and dense graphs. Sparse graphs are for nodes connecting major fast or shortcut nodes together(high ways) and then a more detailed with all the nodes and edges.
Since running dijkstra on massive graphs will not be feasable for long distances you have to do the split above.
Then you do a query from the endpoints to the nearest sparse nodes, and then the sparse nodes to each other.
You keep it all in neo4j, probably too big to keep it in memory. Also way too complex to use a non native graph data base and it would be too slow.
Sparse graphs are small enough to be used in the query.