Untitled.md
<< ---------------------------------------------------------------- >>
--- Last Modified: $= dv.current().file.mtime
Youtube
<< ---------------------------------------------------------------- >>
https://www.youtube.com/watch?v=QrZTmiZSRcw&list=PLjTveVh7FakJOoY6GPZGWHHl4shhDT8iV&index=23
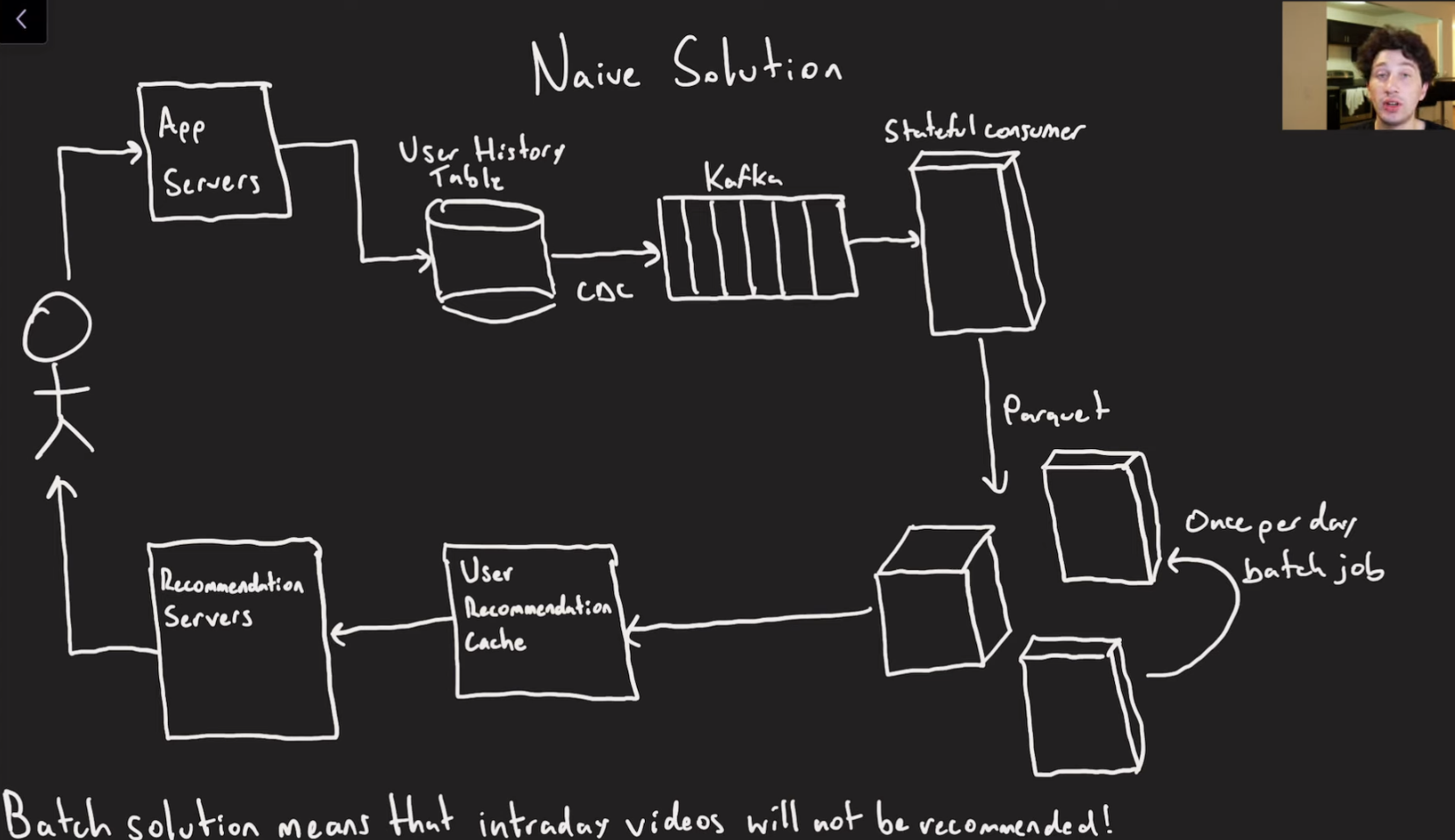
- we want to fetch rec as fast as possible.
- some amount of caching from the front end?
Embeddings (Machine Learning stuff)
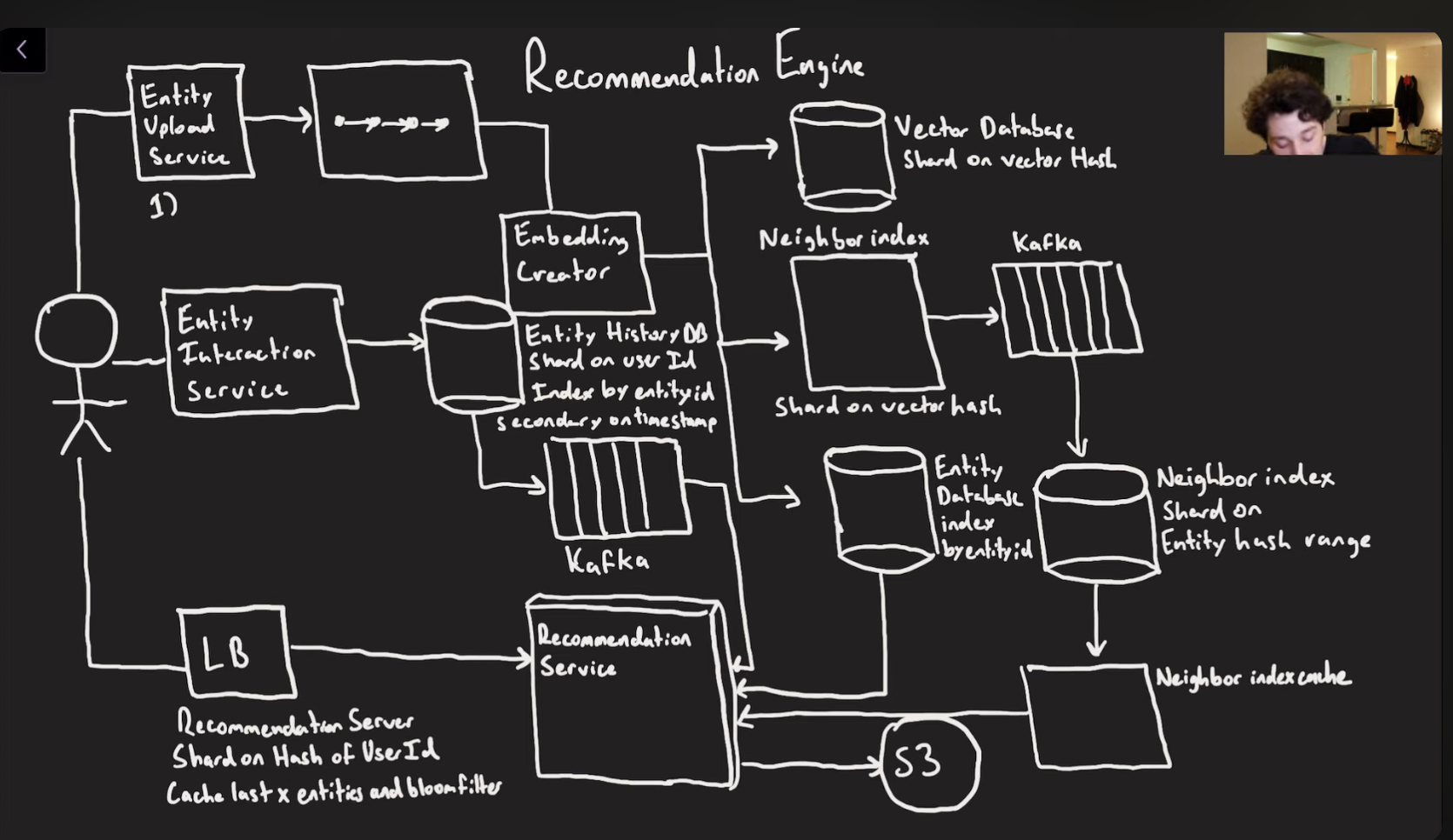
in order to determine similarity between two entities, we need to be able to represent them as numbers(or in this case vectors)
We generate the recommendations in 2 stesp
- retrieval:
- fetch the last x videos a user interacted with
- fetch the last y most similar entities for each of those
- using embedding!
- ranking:
- assign a score to all x.y embeddings
- filter out all entities the user has seen
- sort and return to user
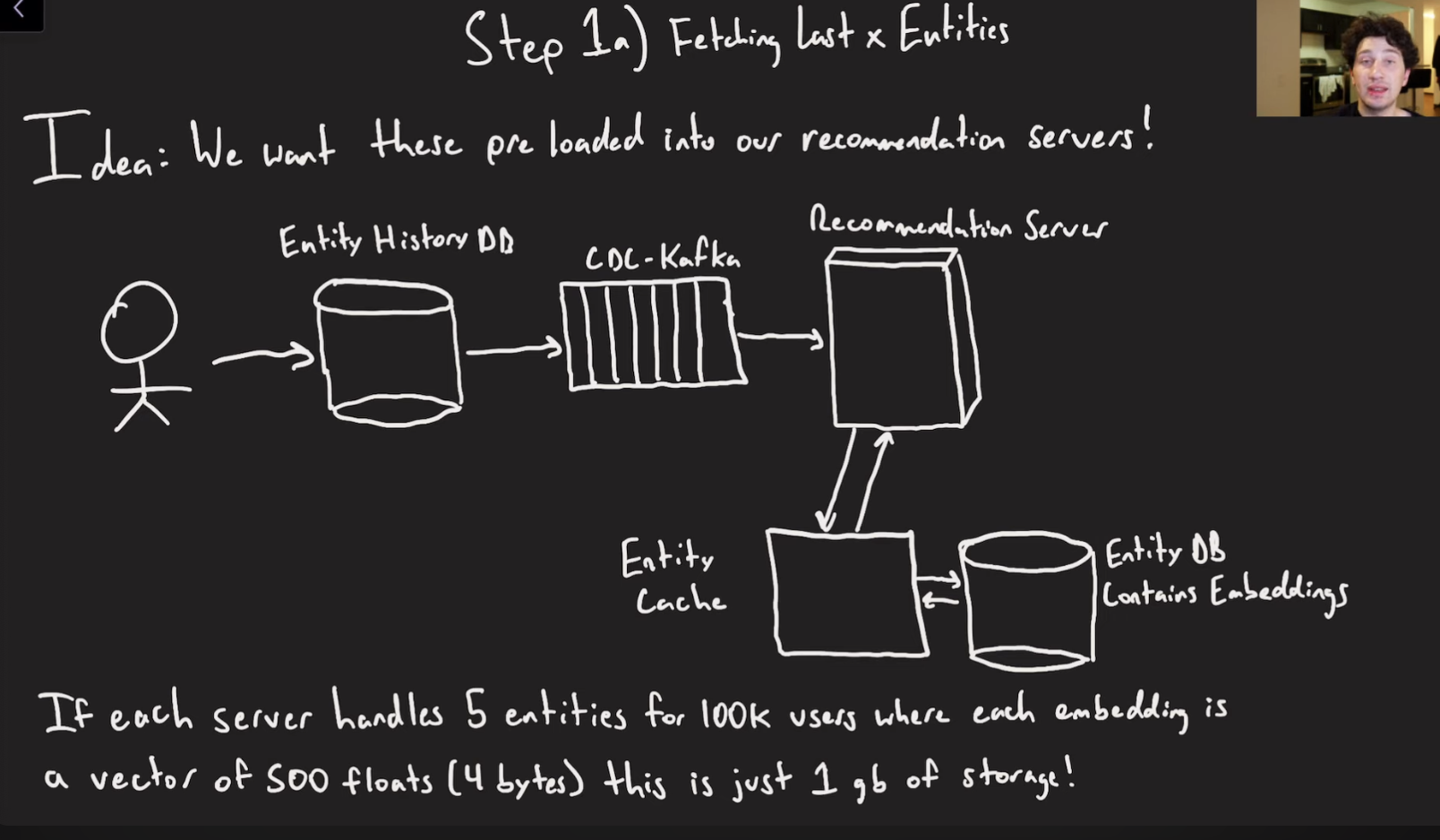
We can pre cache the last x entities we have watched.
Vector databases are good but it takes time to figure out the closest x entities for a given vector → Fetch most similar entities: the vector database is kind of stored in a geohashed database with similar things being on similar vector hashes. This just generalizes to N-dimensions instead of 2.