Untitled.md
<< ---------------------------------------------------------------- >>
--- Last Modified: $= dv.current().file.mtime
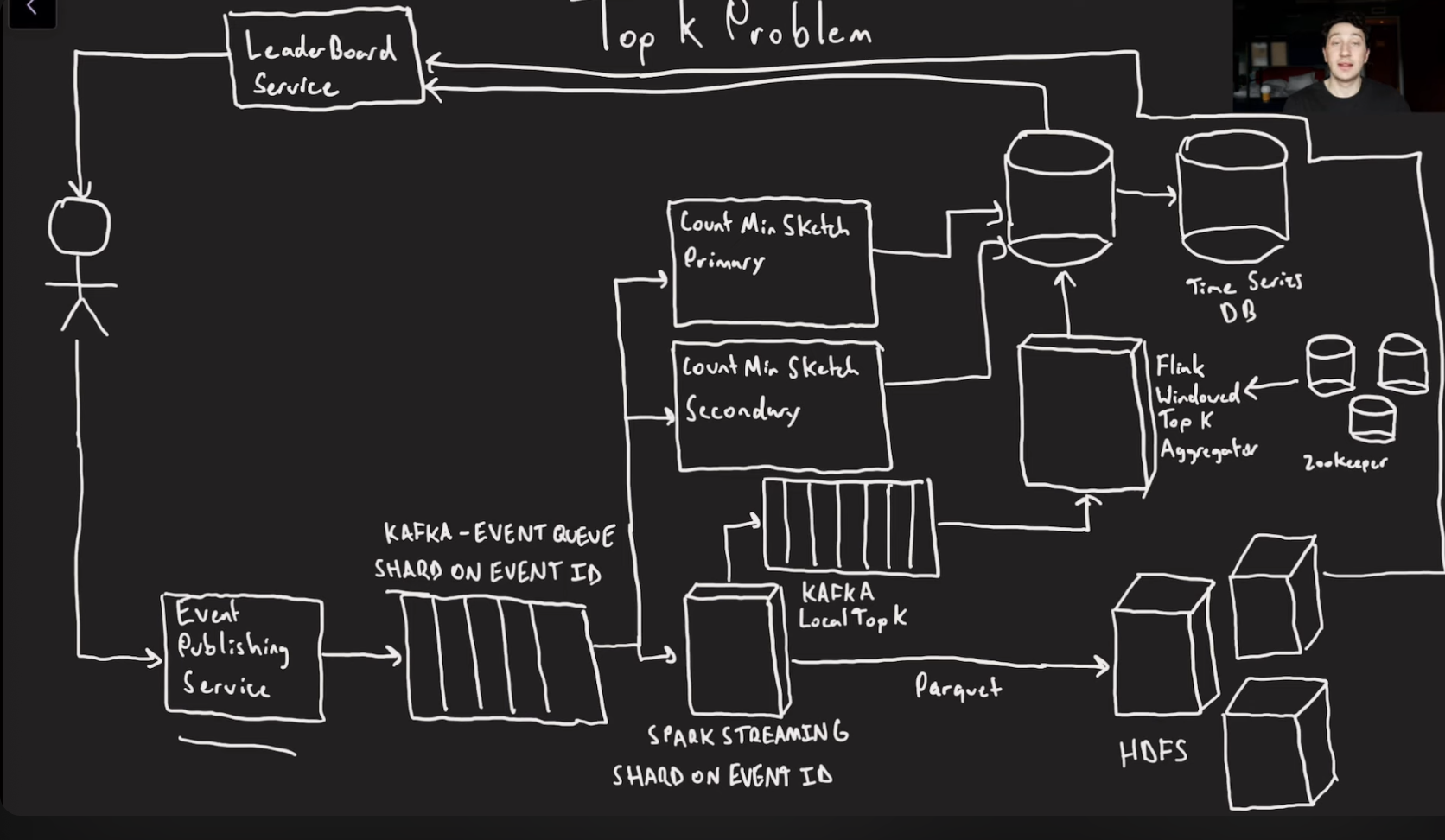
Top K problem
<< ---------------------------------------------------------------- >>
Example: find top k search terms on google, viewed youtube videos, songs on spotify this week,
Reqs:
- lots of incoming event we need to be able to count the occurance of all of them and have a leaderboard for most popular evetns
- should be able to perform this search over arbitrary time ranges
- billions of events per day, k < 1000
All user facing operations should be ASAP also getting exact results can make fetching the eladerboard slow → fast reads, vs percise results.
Percise solution:
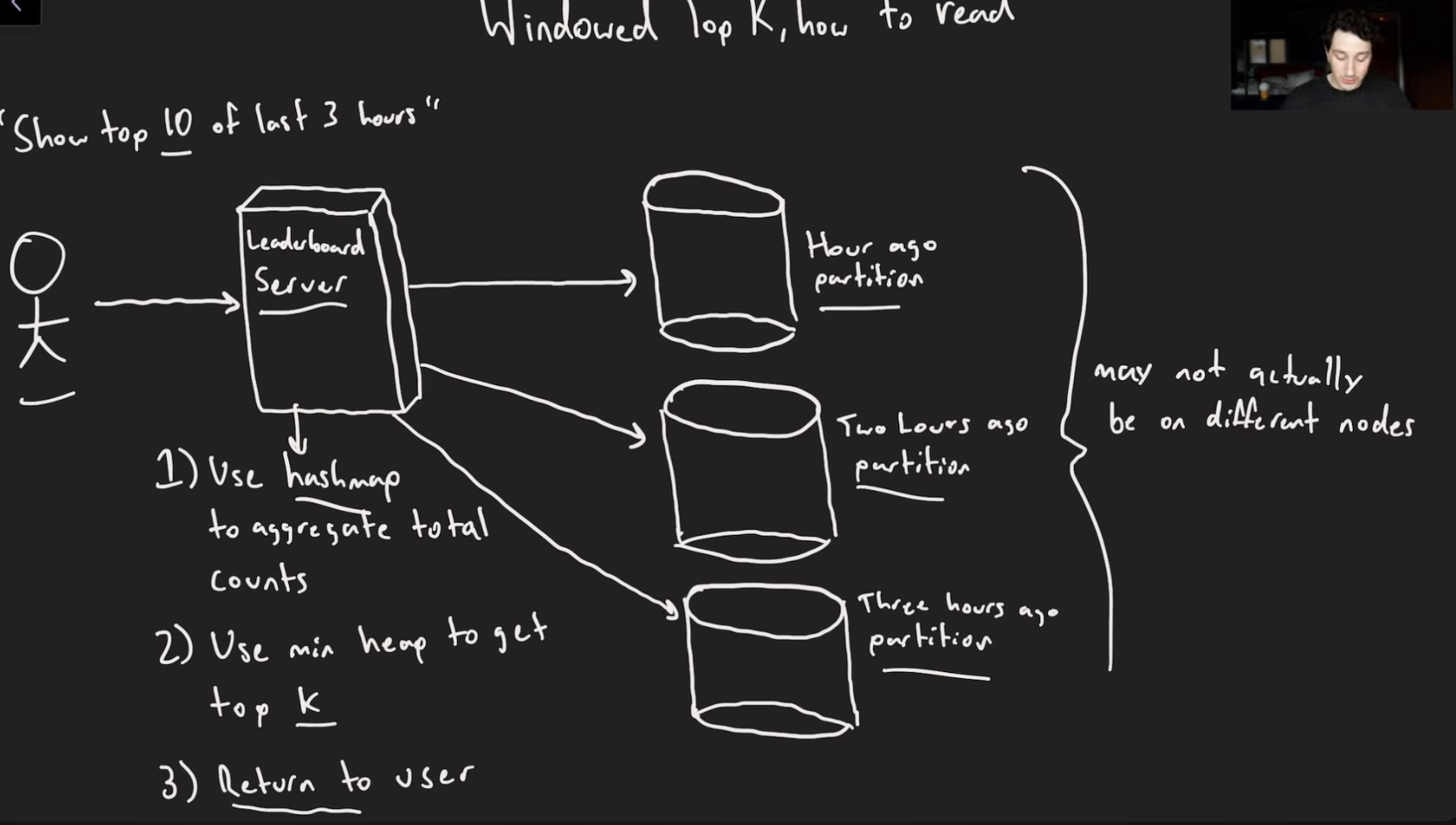
You process every event as they come in, counting them and running batch jobs on the hadoop process after being processed from the stream and put the entries into a min-heap.
Then after this is done on all the nodes, you run a merge a sorted list to merge all the entries.
Depending on the granularity of the time rages this can take a very long time.
This can become a lot faster if we approximate:
Approximation
you cache the top K of the small intervals and just combine them for different time ranges, instead of running the big combine batch job.
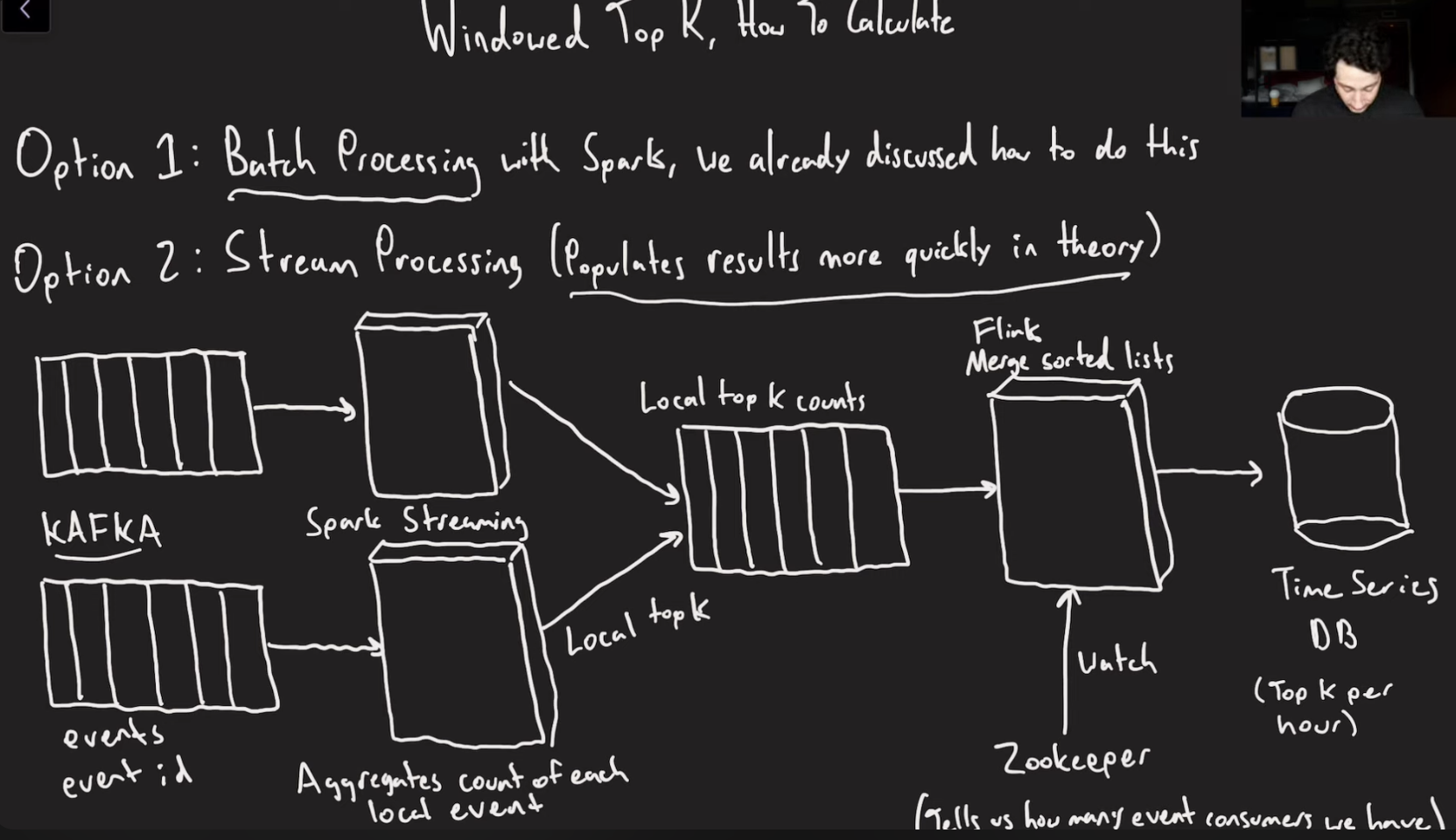
The problem is here that to compute the top K the last flink processer will need to combine the data from all the other spark streaming events and for a system with billions of events the amount of ram we need to do that will be too much so this system is flawed
Count Min Sketch Algorithm
Its an approximation algorithm to figure out teh counts of many incoming elements while using a constant amount of storage.
Basically a 2d matrix used to approximate a count
You can have multiple hash functions(rows) and each hash function can put in the count in multiple buckets(columns). The min of the buckets that the hash puts in the count in is the approximate count
There are mathematical limitations on how big its supposed to be but i wont read them yet prolly.
You can also set up a state machine repliation for fault tolerance(basically a second kafka q that reads and writes to the same stream and time series DB)