Untitled.md
<< ---------------------------------------------------------------- >>
--- Last Modified: $= dv.current().file.mtime
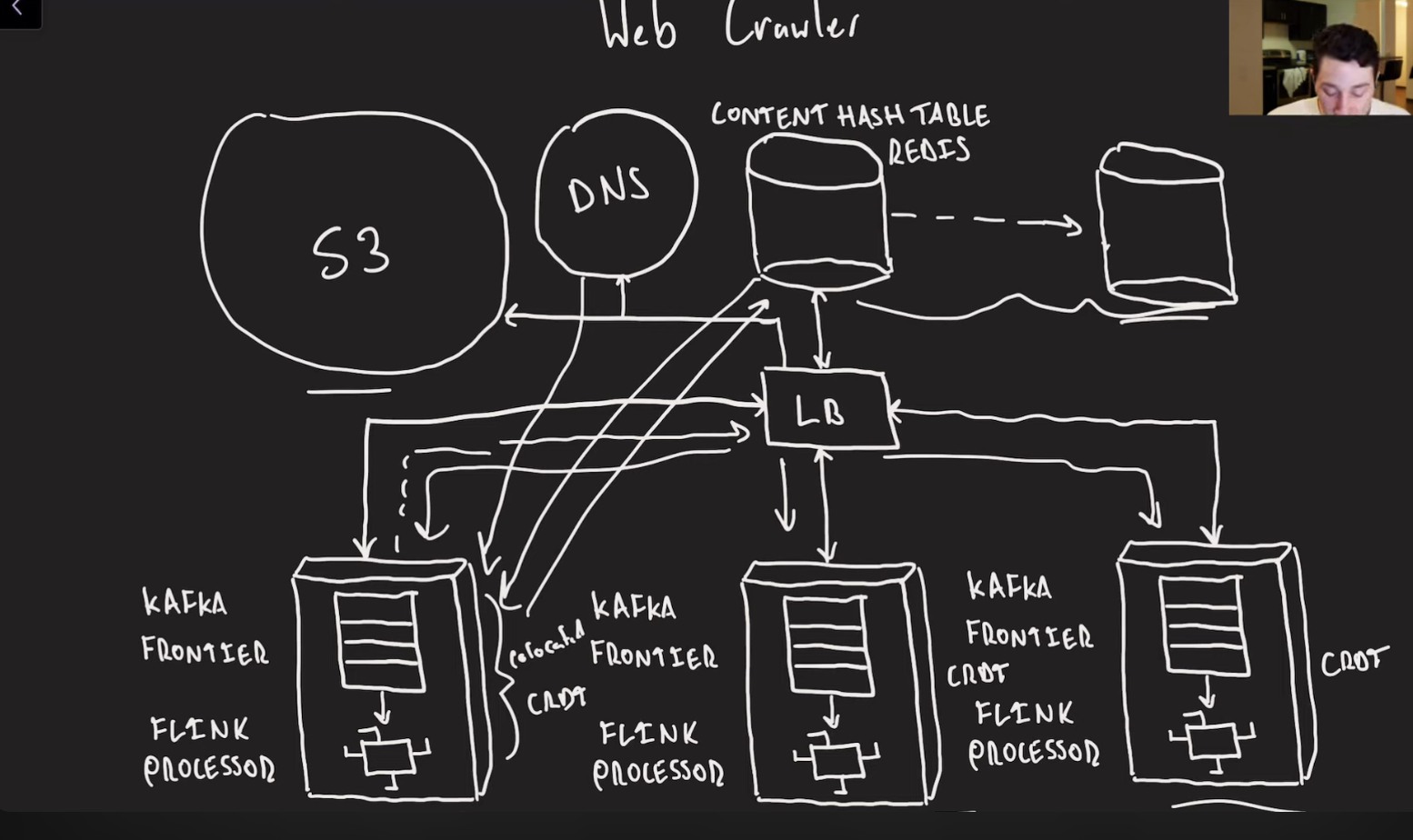
Webcrawler
<< ---------------------------------------------------------------- >>
Just gathering open information
Reqs: Scrape all the content accessible inline and store all of it. Respect website crawling policies(robots.txt) Complete this process within one week. Complete this within one week.
Process of web crawling:
- pull in url from to-crawl list
- check if we have already crawled it
- check if crawling it is compliant with its host’s robots.txt file
- get the IP address of the host via DNS
- make http request to load the contents of the site
- check if we have crawled a different url with identical content
- parse the content
- store the results
- add any referenced URLs to our to-crawl list