03-Application-Architecture Backend Design-Patterns System-Design-Examples
<< ---------------------------------------------------------------- >>
--- Last Modified: $= dv.current().file.mtime
Ad Clicks ;)
<< ---------------------------------------------------------------- >> https://www.youtube.com/watch?v=Zcv_899yqhI its a system that collects and aggregates data on ad clicks. Used by advertisers to track the performance of their ads and campaigns.
Design Steps for Infrastructure and Backend Components
- Requirements
- System Interface and Data Flow
- High-level Design
- Deep Dives
Requirements
Functional Requirements
- user click an ad and they get directed to the advertisements website
- advertisers can query click metricks over time w/ 1 minute as minimum granularity Whats the scale of the system?
10 M ads at any given time 10K ad clicks per second at peak.
Non Functional Requirements
- Scalability to support 10k peak clicks per s
- low latency analytics queries < 1s
- Fault tolerance
- Data integrity
- As realtime as possible (this means streams)
- Idempotency(an operation has the same effect regardless of how many times it’s executed, as long as the input parameters remain the same) of ad clicks
Interface and Data Flow
Outlining what Data the system receives and what it outputs.
Input:
- click Data
- Advertiser queries Output:
- redirection
- aggregated click metrics
Data Flow:
- Click Data comes into the system
- User is redirected
- Click data validated(idempotency)
- Log the click data
- Aggregate the click data to be readable
- Aggregated data queried by the advertisers
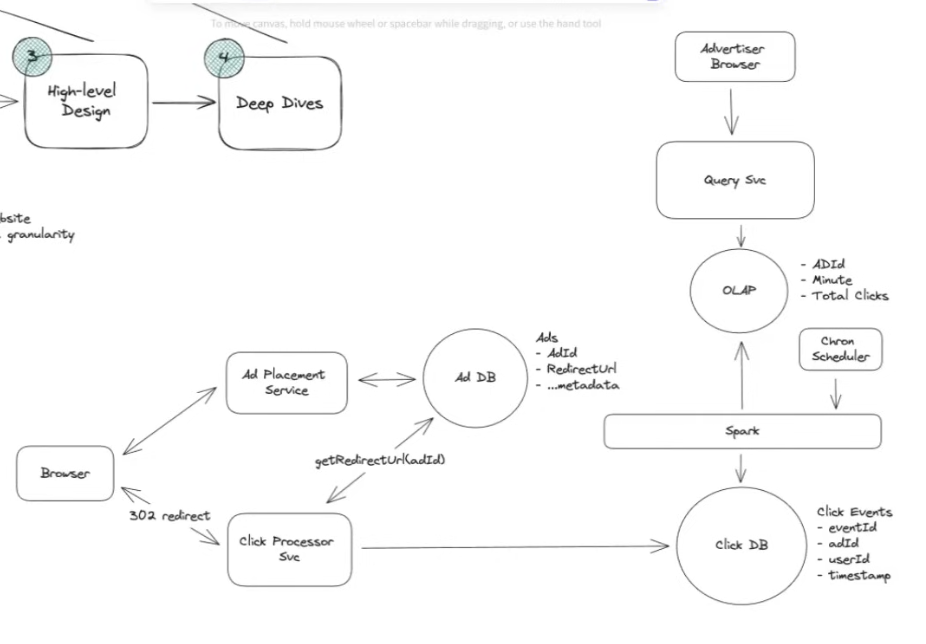
High Level Design
Click DB: has to be optimized for a lot of writes (10k clicks per second) to gather the required information:
- 1st solution: use Cassandra: it uses a sorted structure resembeling LSMs. Inserts and updates into a log like structure(mem table in memory) and it flushes it to disk periodically.
- But this also causes the read queries used to aggregate data to be very slow(select a bunch of relational stuff about the users that clicked between a certain timestamp and grouped by id for example)
- 2nd Solution:
- Use a Spark layer: It automatically aggregates the click DB coming in in 1min intervals and puts it into an OLAP(Online Analytical Processing)
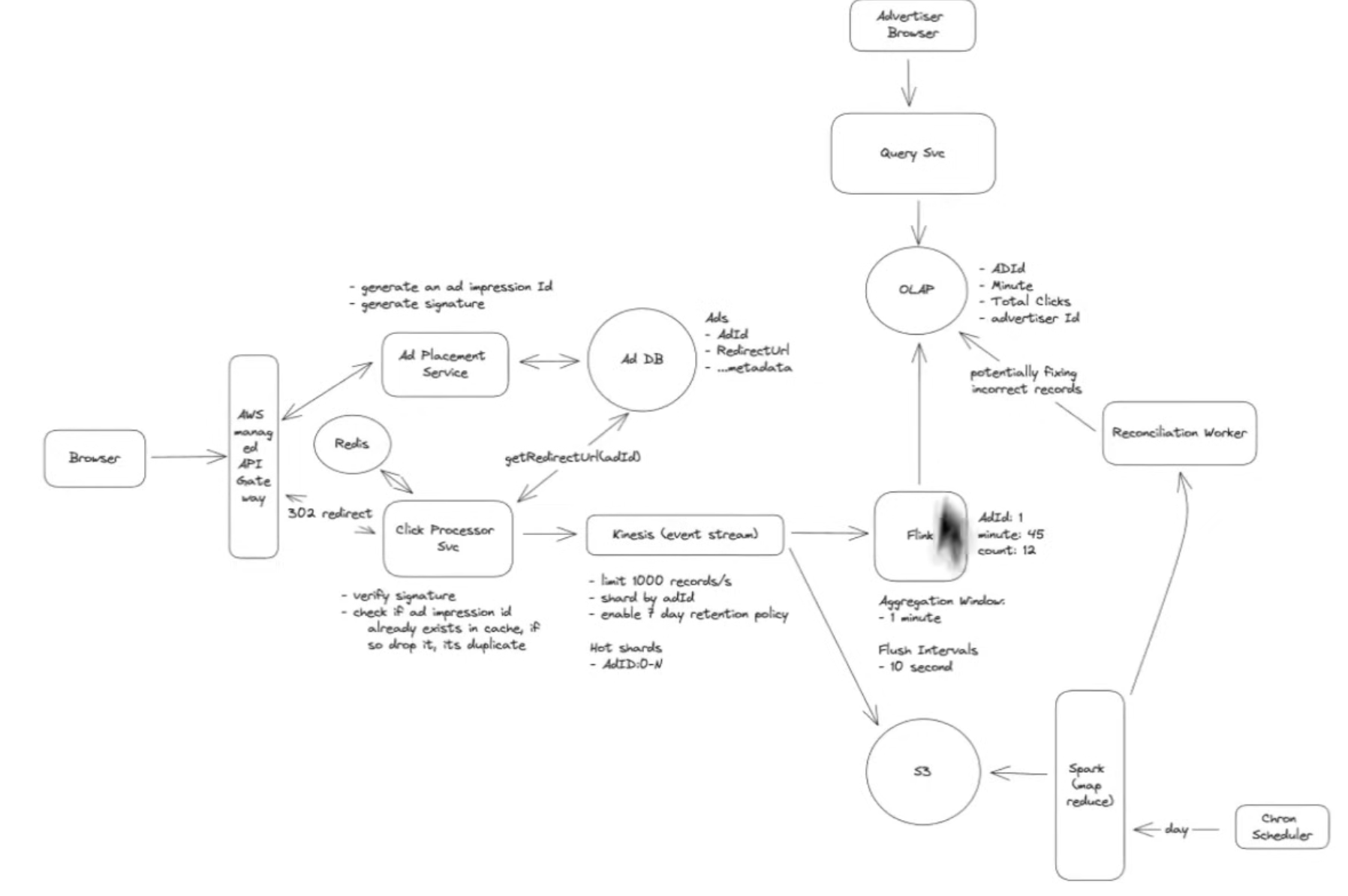
Deep Dives
- Lowering Latency:
- You can reduce the number of times the cron job runs Spark but it is pretty computationally expensive and at some point there will be too much over head: need to redesign the system:
- introduce a stream like Kinesis: when the clicks come in they go to the stream → then to a stream aggregator sth like Flink
- Flink keeps an in memory data structure.
- You specify an aggregation window for example 60s and once the timelimit is reached, it aggregates the in memory data structure and write it directly to the database(OLAP)
- You have flush intervals as well, interval that intermediary results are flushed from the system. You can set it to 10s and flush the partial data to the OLAP.
- You can reduce the number of times the cron job runs Spark but it is pretty computationally expensive and at some point there will be too much over head: need to redesign the system:
- Scalability to support 10k CPS:
- you can scale the click processor horizontally,
- have a load balancer at the front thats responsible for the click processor load balancing.
- Scaling the Stream: kinesis you can Shard todo by ad ID, and scale the flink based on how many shards you have?
- what happens if you have a hot shard(for example there is a new ad with lebron and everyone is clicking on it, how do you scale the stream and the flink?)
- Fruther partition the data
- celebrity problem: end up adding some number to the Shard Key: basically partition the shard into N different Shards and scale accordingly
- Since Flink is in memory it can scale a lot better so you dont need to do multiple flink jobs for the different partitions of the hot shard.
- what happens if you have a hot shard(for example there is a new ad with lebron and everyone is clicking on it, how do you scale the stream and the flink?)
- Fault Tolerance and Data Integrity:
- Kafka and Kinesis are usually managed so no need to think too much about them going down.
- But the Flink tasks could go down, so have to have retention policies in the stream (7 days or sth else configurable)
- Check Pointing:
- Flink can write their State periodically to persistant Storage(S3). By default its around 10 15 minutes
- This doesnt really make any sense tho in this case, since the aggregation window for our stream is a minute. so at most were a minute behind and there is no need to reprocess the entire 10 15 minutes.
- Introduce Periodic Reconciliation:
- have a job that runs maybe once a day or hour, take the results from the batch processing solution earlier
- kinesis can dump the raw click data into S3, then you can aggregate it through a spark running once a day or hour
- Have a reconciliation worker and get the aggregation from spark that will potentially fix in correct records.
- Basically you use the first design as a corrector
- have a job that runs maybe once a day or hour, take the results from the batch processing solution earlier
- Lambda and Kapa Architectures:
- What they are: data processing architectures for handling large scale data processing systems.
- Kapa for stream processing ⇒ real time processing layer ⇒ the kinesis to flask to OLAP is a kapa architecture
- Lambda architecture is the first design and uses batching. But it does have a real time layer that is not guaranteed to be accurate.
- The final diagram combines the two
- Idempotency of ad Clicks:
- Cant really track user ID, becasuse some services might not require logins and we still need to track those.
- Generate Ad Impression ID.
- generate a unique impression for each instance of an ad served.
- You implement this on the ad placement service and have it be a part of the ad served by the server.
- You can have a redis cache on the click processer server that checks if that ID has been tagged before, and drops the entire request if it has
- This can be exploited if a bot just generates random impression IDs and sends them to the server
- Sign it in the Ad placement service with a private key and see if the signed impression ID is verified or not.