Untitled.md
<< ---------------------------------------------------------------- >>
--- Last Modified: $= dv.current().file.mtime
metrics
<< ---------------------------------------------------------------- >>
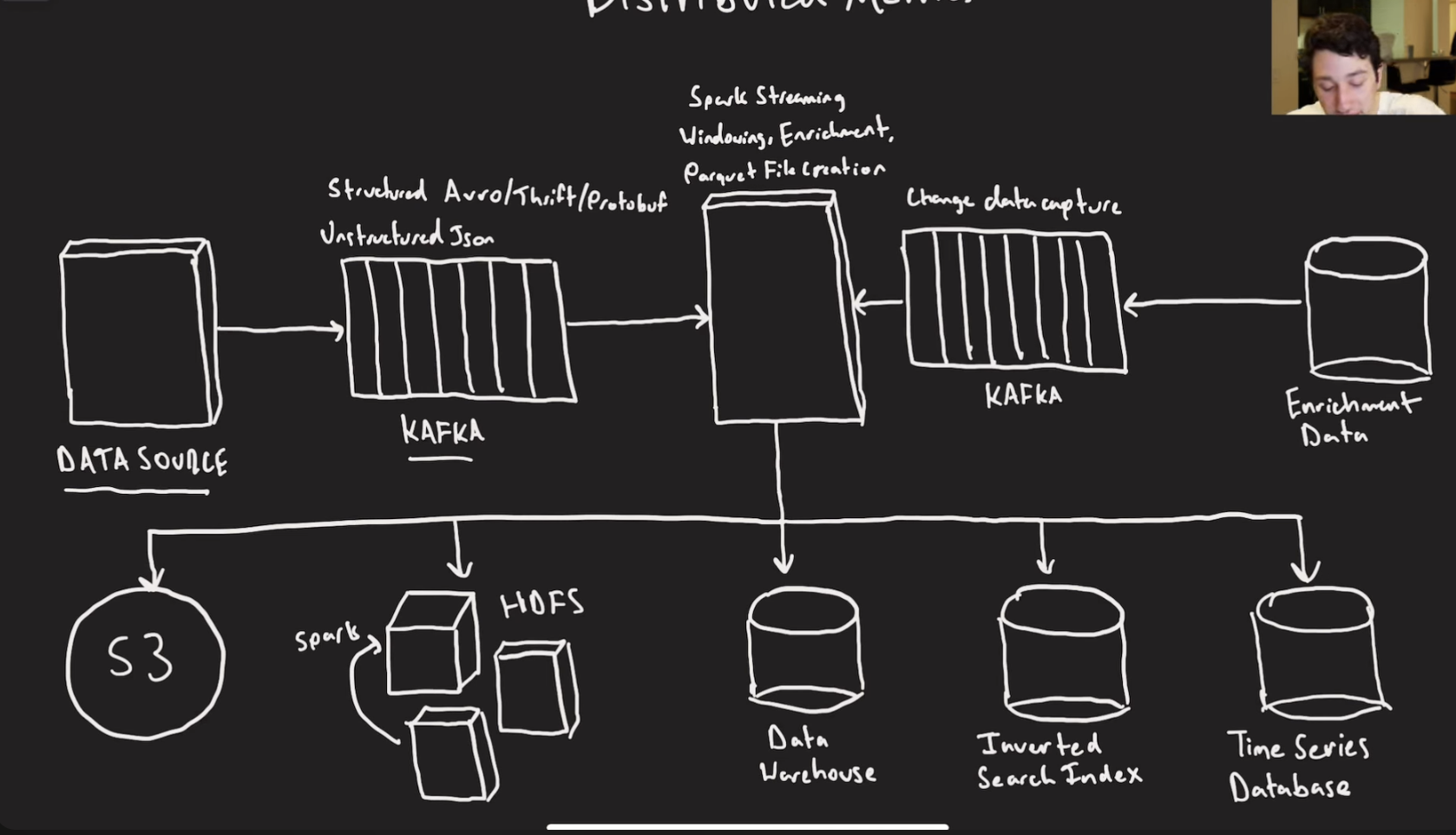
kinda like the Ad Click Aggregator stuff
since the servers will output a lot of data you will not be able to consume all of them as fast as they come in, so you put them in a stream like kafka that persists. You aggregate by something like time (tumbling or hopping window)
Then you put the aggregated data into a time series sink data base.
Something that uses Hypertables and chunk table design.
Text Logs: there will be a lot of text logs in our time series database → we can put it in a distributed search index and create local inverted indexes for logs.
Structured Data: sometimes we want to stroe data from our application that we already know the schema of.
We can give the schema to our stream consumer and publisher like flink and serialize it that way from kafka.
For unstructured Data: we can aggregate in flink to a file and dump it in HDFS and run a spark job to structure the data.
We can store all this data in Parquet Files → it has column oriented storage, run length encoding/dictionry encoding and predicate pushdown via file metadata(additional information for the column like min/max/mean)
We can store it in S3, pull it into hadoop and run a spark job on the files. Or just store all of them on hadoop